
Repair
Repairs must be completed regularly to maintain Cassandra nodes.
AxonOps provide two mechanisms to ease Cassandra repairs:
-
Scheduled repair
-
Adaptive repair service
Scheduled repair¶
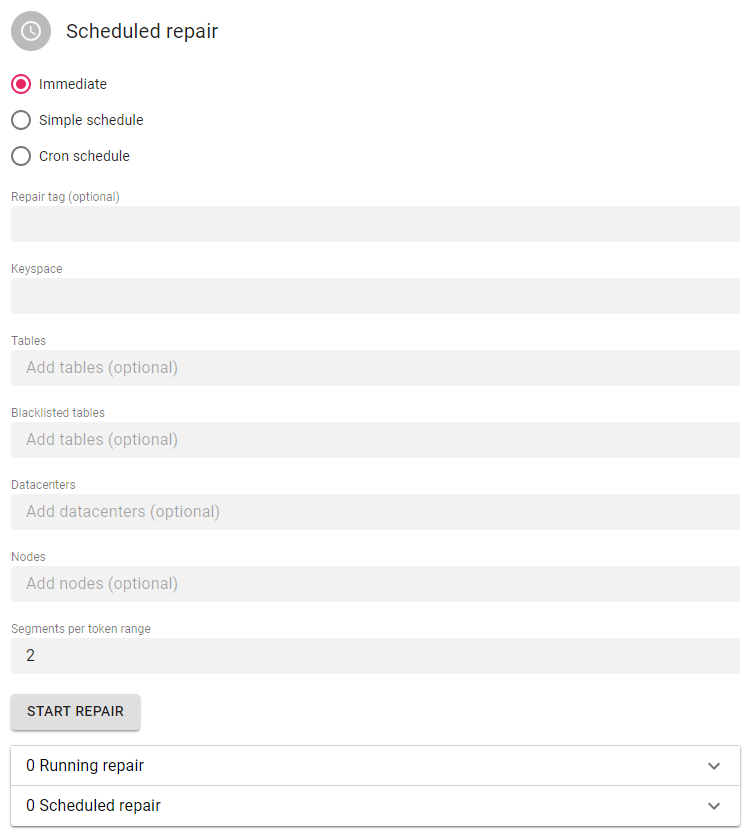
You can initiate three types of scheduled repair:
- Immediate scheduled repair: these will trigger immediately once
Infomy
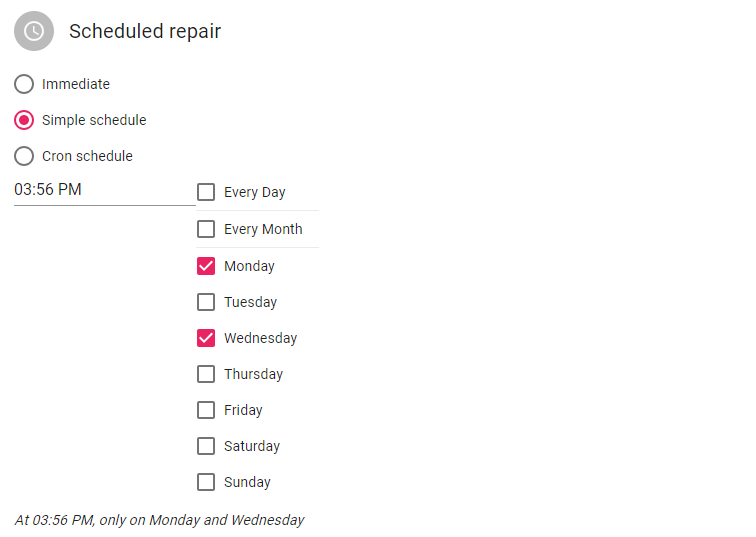
- Simple scheduled repair: these will trigger base on the selected schedule repeatedly
Infomy
- Cron schedule repair: Same as simple scheduled repair but the schedule will be based on a Cron expression
Infomy

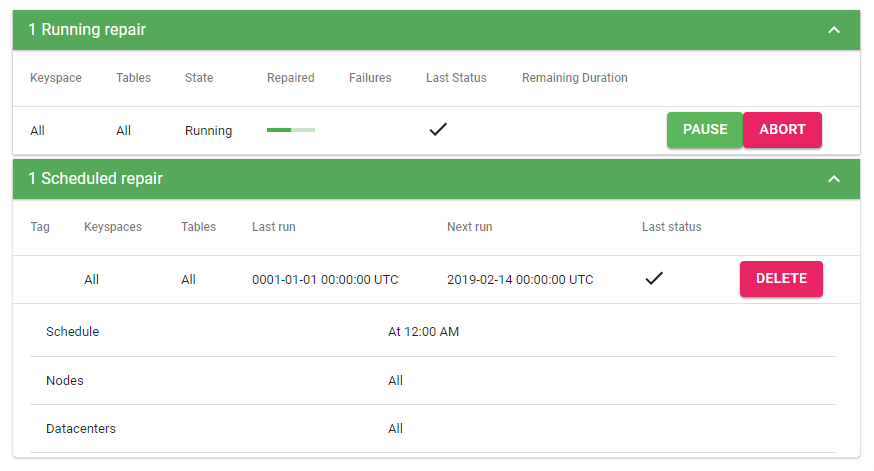
The following capture presents a running repair that has been initiated immediately and a scheduled repair that is scheduled for 12:00 AM UTC:
Infomy
Adaptive repair service¶
Since AxonOps collects performance metrics and logs, we built an “Adaptive” repair system which regulates the velocity (parallelism and pauses between each subrange repair) based on performance trending data. The regulation of repair velocity takes input from various metrics including CPU utilisation, query latencies, Cassandra thread pools pending statistics, and IOwait percentage, while tracking the schedule of repair based on gc_grace_seconds for each table.
The idea of this is to achieve the following:
- Completion of repair within gc_grace_seconds of each table.
- Repair process does not affect query performance.
- In essence, adaptive repair regulator slows down the repair velocity when it deems the load is going to be high based on the gradient of the rate of increase of load, and speeds up to catch up with the repair schedule when the resources are more readily available.
- This mechanism also doesn't require JMX access. The adaptive repair service running on AxonOps server orchestrates and issues commands to the agents over the existing connection.
Infomy
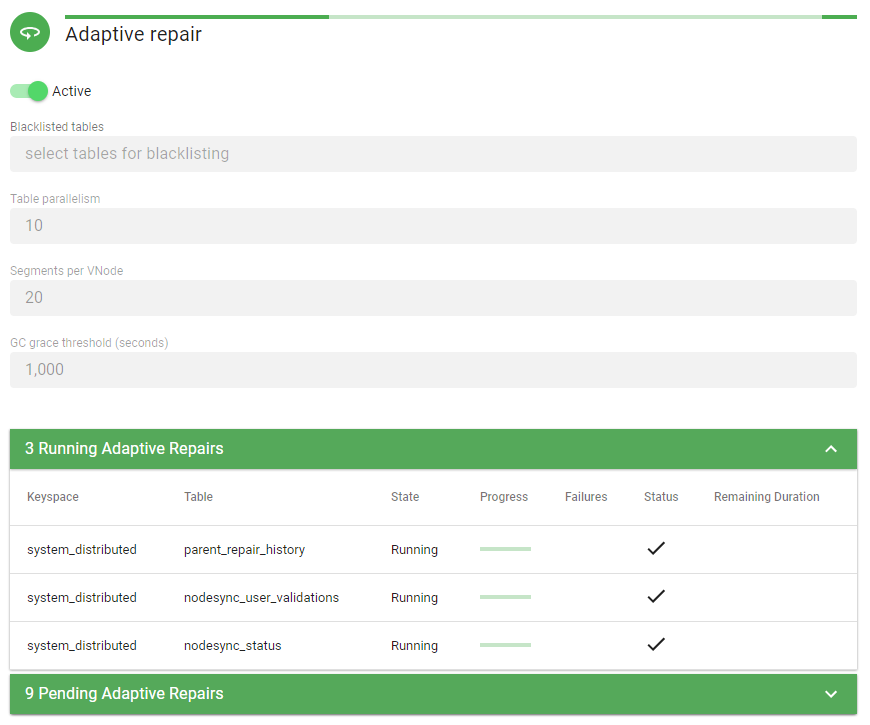
If you want to keep the tables as fresh as possible we recommend to increase the
table parallelismto be greater than the total number of tables of your cluster and reduce thesegments per VNodeto generate less repair requests.
From a user’s point of view there is only a single switch to enable this service. Keep this enabled and AxonOps will take care of the repair of all tables for you. You can also customize the following:
-
Blacklist some tables
-
Specify the number of tables to repair in parallel
-
Specify the number of segments per VNode to repair
-
The GC grace threshold in seconds: if a table has a gc grace lesser than the specified value, it will be ignored from the adaptive repair service