
Restore a whole cluster from a remote backup with different IP addresses¶
Follow this procedure when you have lost all nodes in a cluster and they have been recreated in the same topology (Cluster, DC and rack names are all the same and the same number of nodes in each) but the replacement nodes have different IP addresses from the original cluster.
NOTE: This process is for disaster recovery and cannot be used to clone a backup to a different cluster
Prepare the cluster for restoring a backup¶
Before you start, ensure that Cassandra is stopped on all replacement nodes and that their data directories are empty
sudo systemctl stop cassandra
sudo rm -rf /var/lib/cassandra/commitlog/* /var/lib/cassandra/data/* /var/lib/cassandra/hints/* /var/lib/cassandra/saved_caches/*
Allow the AxonOps user to write to the Cassandra data directory on all nodes
sudo chmod -R g+w /var/lib/cassandra/data
The commands above assume you are storing the Cassandra data in the default location
/var/lib/cassandra, you will need to change the paths shown if your data is stored at a different location
As the IP addresses of the replacement Cassandra nodes are different to the old cluster you will need to update the
seeds list in cassandra.yaml to point to the IPs of the nodes that are replacing the old seeds. For package-based
installations (RPM or DEB) you can find this in /etc/cassandra/cassandra.yaml or for tarball installations it should
be in <install_path>/conf/cassandra.yaml.
Manually configure the AxonOps Agent host IDs¶
AxonOps identifies nodes by a unique host ID which is assigned when the agent starts up. In order to restore a backup to a node with a different IP address you must manually assign the AxonOps host ID of the old node to its new replacement.
In order to restore the whole cluster from a backup you will need to apply the old AxonOps host ID to all nodes in the replacement cluster.
The host ID of the old node can be found on the Cluster Overview page of the AxonOps dashboard
Infomy
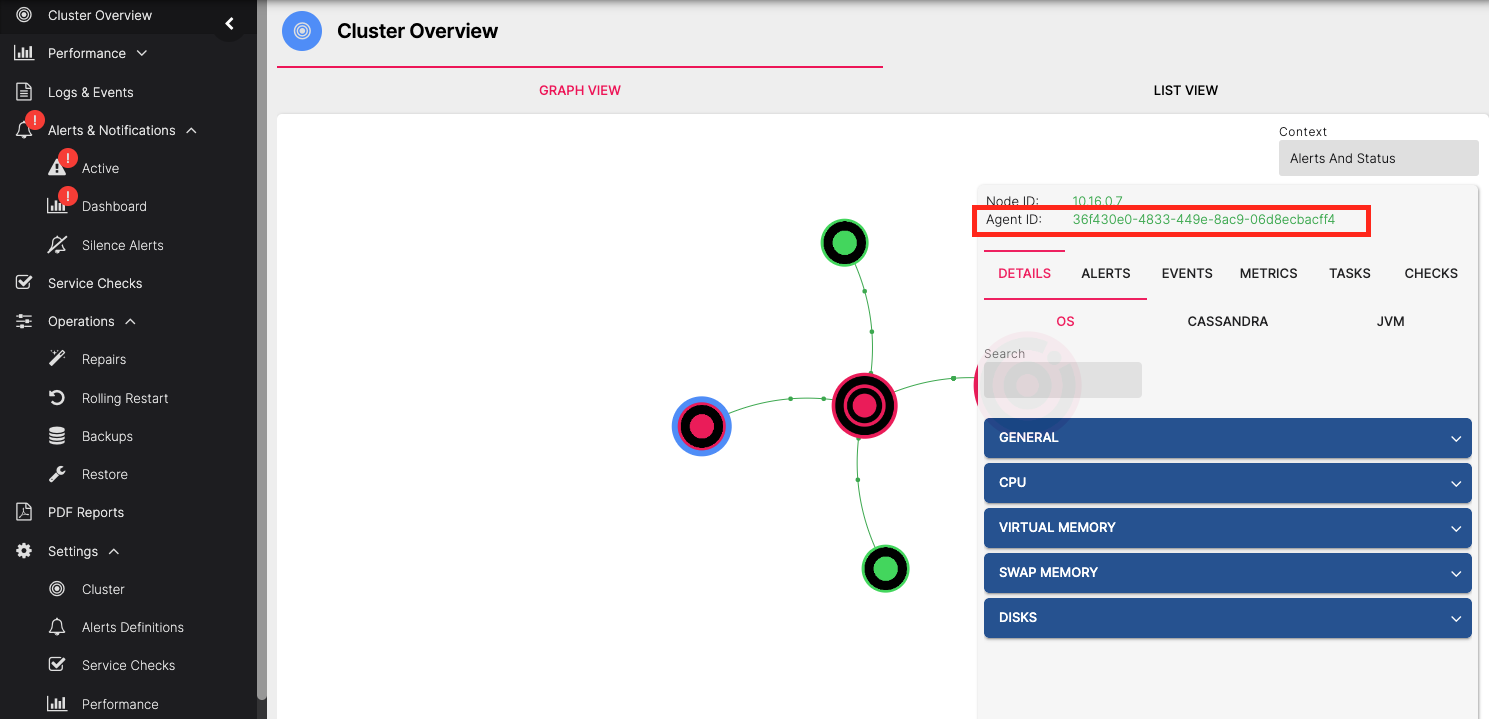
If you still have access to the old server or its data then its host ID can also be found in the file /var/lib/axonops/hostId
Apply the old node's host ID to its replacement¶
Ensure the AxonOps Agent is stopped and clear any data that it may have created on startup
sudo systemctl stop axon-agent
sudo rm -rf /var/lib/axonops/*
Manually apply the old node's host ID on the replacement (replace the host ID shown with your host ID from the previous steps)
echo '24d0cbf9-3b5a-11ed-8433-16b3c6a7bcc5' | sudo tee /var/lib/axonops/hostId
sudo chown axonops.axonops /var/lib/axonops/hostId
Start the AxonOps agent
sudo systemctl start axon-agent
In the AxonOps dashboard you should see the replacement nodes start up and take over from the old nodes after a few minutes.
Restore the backup¶
Open the Restore page in the AxonOps Dashboard by going to Operations > Restore
Infomy
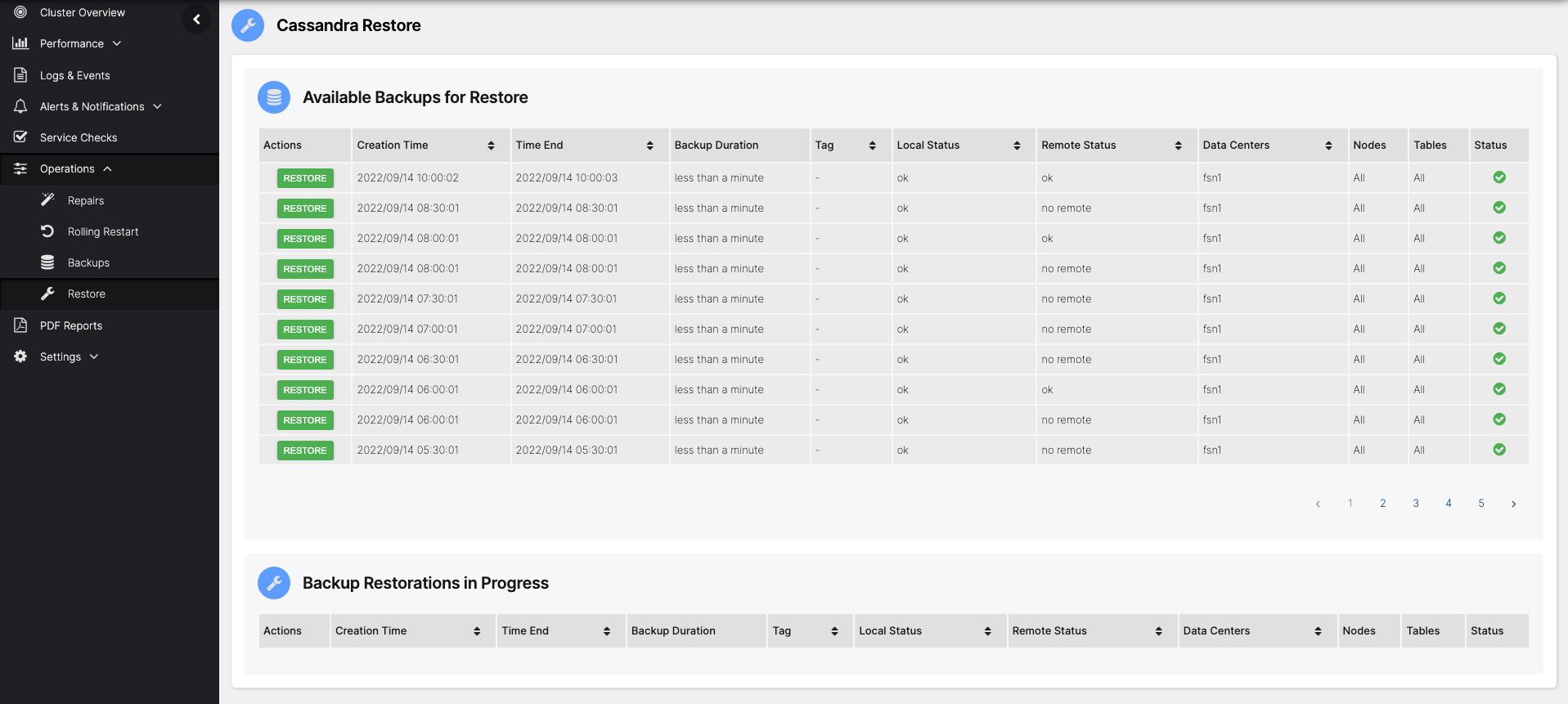
Choose the backup you wish to restore from the list and click the RESTORE button
This will show the details of the backup and allow you to restore to all nodes or a subset using the checkboxes in the Nodes list.
Infomy
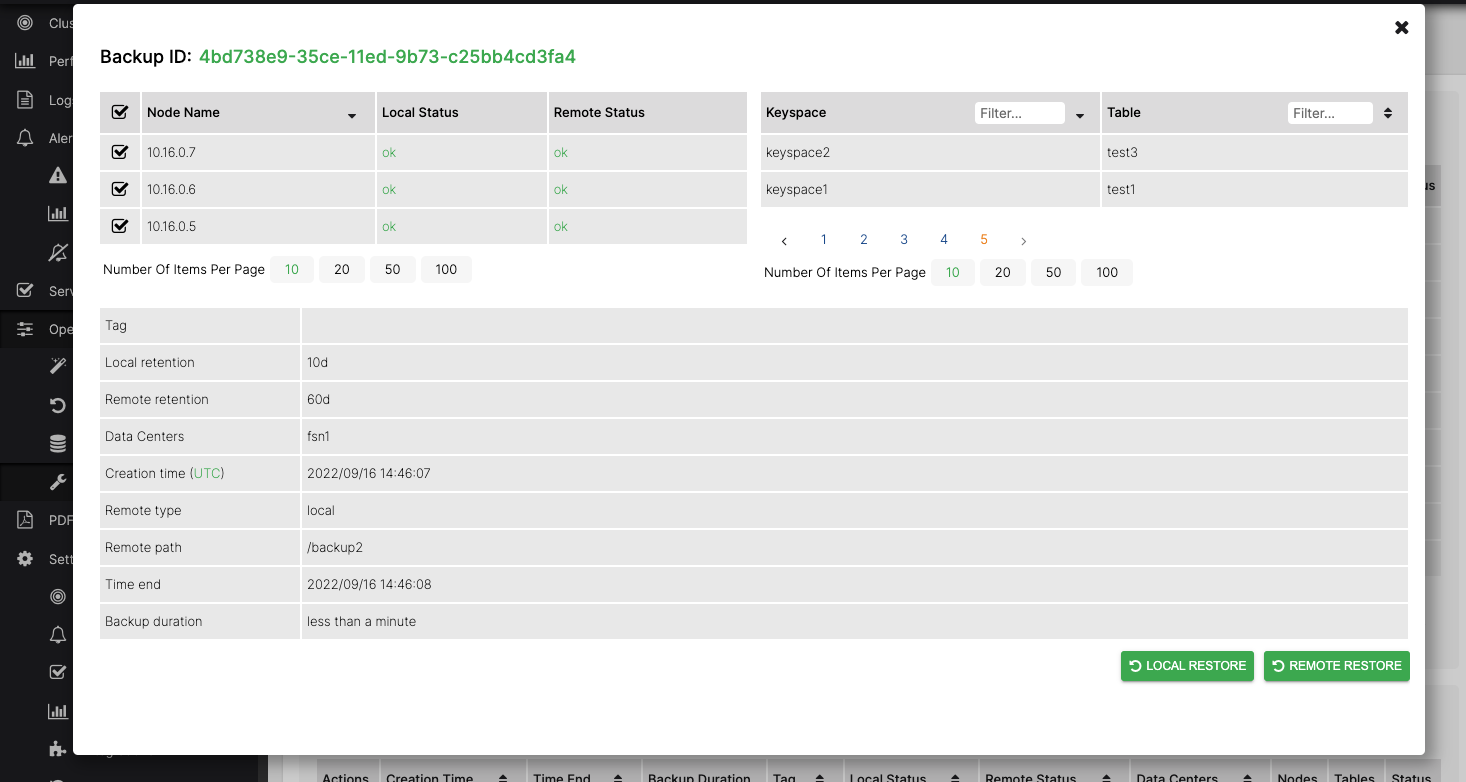
Select all nodes in the checkbox list then start the restore by clicking the REMOTE RESTORE button.
The restore progress will be displayed in the Backup Restorations in Progress list
Infomy

After the restore operation has completed successfully, fix the ownership and permissions on the Cassandra data directories on all nodes in the cluster
sudo chown -R cassandra.cassandra /var/lib/cassandra/data
sudo chmod -R g-w /var/lib/cassandra/data
Start cassandra on the restored nodes one at a time, starting with the seeds first
sudo systemctl start cassandra
After the whole cluster is started up you should be able to see the replaced nodes with their new IP addresses
in the output of nodetool status. You may still see the IP addresses of the old cluster nodes in the output of
nodetool gossipinfo, these should clear out automatically after a few days or they can be manually tidied up by
performing a rolling restart of the cluster.